#Go to link to extract data
#https://finance.yahoo.com/quote/FB/history?p=FB&.tsrc=fin-tre-srch
#After that apply this formula to all H column =(C1/B1 - 1) * 100 and
#this to I column =(1 - D1/B1 ) * 100
#reason is to determine percentage variation. Next project automate this with python
#Your data should look like image below.
#facebook_2019
import pandas as pd #import libraries
import matplotlib as plt
#code below is from other year
#Before opening the excel, erase the headlines(e.g Date, open, .....) as it could
#cause problems to extract data. I will come back to reduce this manual job. hopefully with code.

# Procceed to the path of your csv (comma separated values or excel
path = "FB_2019.csv" # This code redirects to path of file,
df = pd.read_csv(path, header=None)
headers= ['date','open','High','low','close','Adj Close','Volume', 'range_high', 'range_low']
df.columns = headers
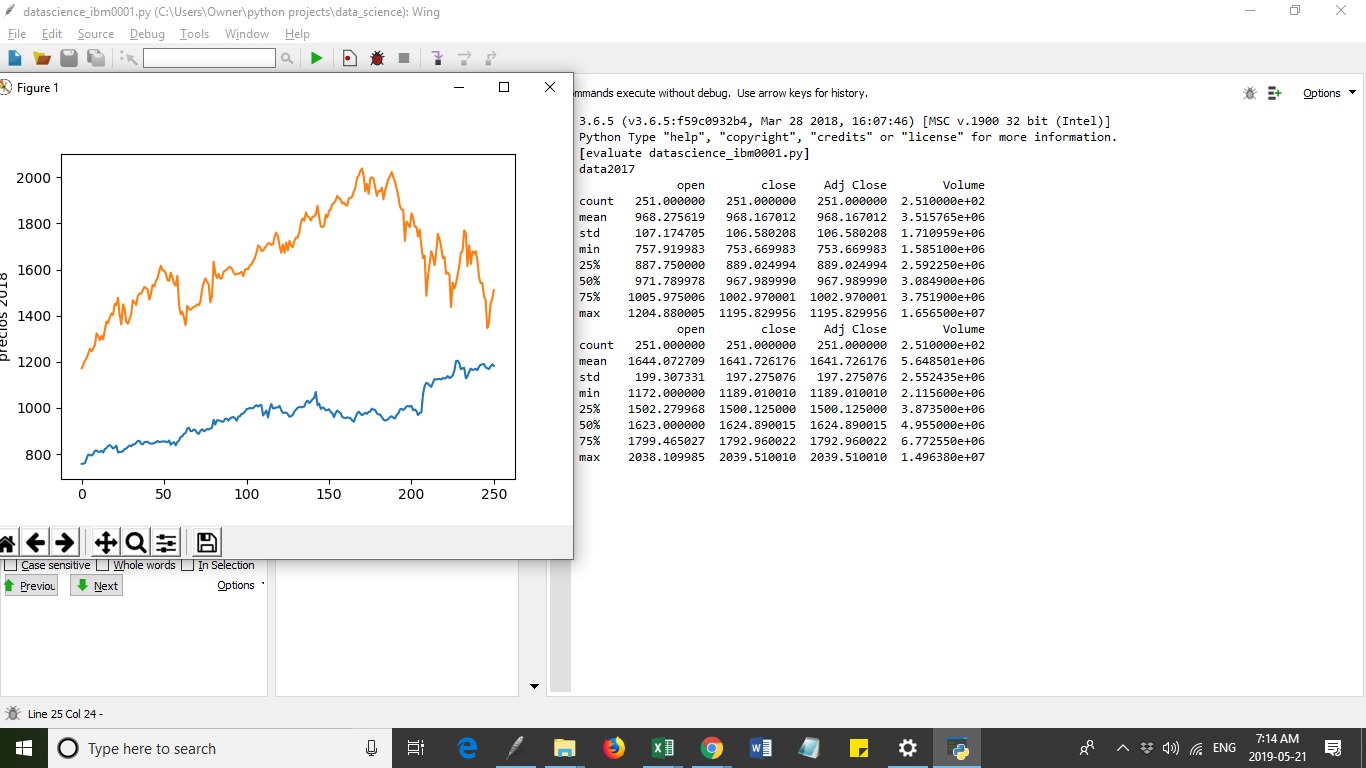
data2019 = df[['date','open','High','low','close','Adj Close','Volume','range_high', 'range_low']].describe()
#code above replace'date' or 'open' by 'low' or any other parameter in headers
print('data2019')
print(data2019)
year_of_selection = df[['open']]
import matplotlib.pyplot as plt
plt.plot(year_of_selection)
plt.ylabel('prices 2019')
plt.show()
#You could choose any column you want by modifying data 2019